みなさん、こんにちは、
みむすたーです。
今日は、普段の記事のテイストから少し変えて、実験的な記事にします。
最近、私は人工知能関連の書籍を読んでいて、その中で一つ疑問が生まれました。
簡単にディープラーニングという人工知能の技術が学習を行うプロセスを説明しておきます。
まず、ディープラーニングが学習を行うためには、問題と問題の答え用意します。
人工知能エンジニア界隈ではこの問題と問題の答えのデータに、
Google summer of Codeというイベントで発足されたscikit-learnプロジェクトが作成したデータ、
を使用することが一般的です。
scikit-learnのデータにはいくつか種類があるのですが、
今回扱うscikit-learnのデータは、手書きの10進数のデータ(0〜9の数字)です。
例えば、以下のような感じ。

上の例を見ても既に人間に判断できるかどうか怪しい数字もありますが…
ちなみに、書き崩しているデータを使用しているのは、
柔軟に手書きデータを判断できるようにするためです。
とりあえず、このような手書きのデータを正しく判断する人工知能を作り、
その人工知能が間違えたデータをみなさんに見てもらいます。
それでは、いきましょう。
もくじ
検証用のソースコード
%tensorflow_version 2.x
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers, models
from sklearn import datasets
# 順伝播
model = models.Sequential()
# 入力層 - 隠れ層 のモデル追加
model.add(layers.Dense(32,activation='relu',input_shape=(64,),name="relu_layer"))
# 隠れ層 - 出力層 のモデル追加
model.add(layers.Dense(10,activation='softmax',input_shape=(32,),name="softmax_layer"))
# 最適化関数=adam、誤差関数=クロスエントロピー、評価関数=多項分類器、で設定
model.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=["categorical_accuracy"])
# 手書きの10進数データを取り出す
datas = datasets.load_digits().data
target_index_list = datasets.load_digits().target
# one-hot表現への変換
target = np.zeros((len(target_index_list),10))
for i, target_index in enumerate(target_index_list):
target[i][target_index] = 1
# 学習用データとテストデータを分ける
data_partition = len(datas) * 2 // 3
learn_datas = datas[0:data_partition]
learn_target = target[0:data_partition]
test_datas = datas[data_partition:len(datas)]
test_target = target[data_partition:len(datas)]
# 学習開始
history = model.fit(learn_datas,learn_target,batch_size=len(learn_datas),epochs=2000,verbose=0)
# 学習後データ取得
middle_weight, middle_bias, last_weight, last_bias = model.get_weights()
# テストデータで出力を試みる
middle_u = np.dot(test_datas, middle_weight) + middle_bias
middle_out = np.maximum(0, middle_u)
last_u = np.dot(middle_out, last_weight) + last_bias
last_out = np.exp(last_u) / np.sum(np.exp(last_u))
# 間違ったデータをプロットする
fig = plt.figure()
plt.gray()
count = 0
count_max = 49
for i,test_data in enumerate(test_datas):
if count == count_max:
break
if 0 == test_target[i][last_out[i].argmax()]:
count = count + 1
ax = fig.add_subplot(np.sqrt(count_max),np.sqrt(count_max),count)
ax.imshow(test_data.reshape(8,8))
print("ai = " + str(last_out[i].argmax()) + ", " + "correct = " + str(test_target[i].argmax()))
plt.show()プログラムの実行結果
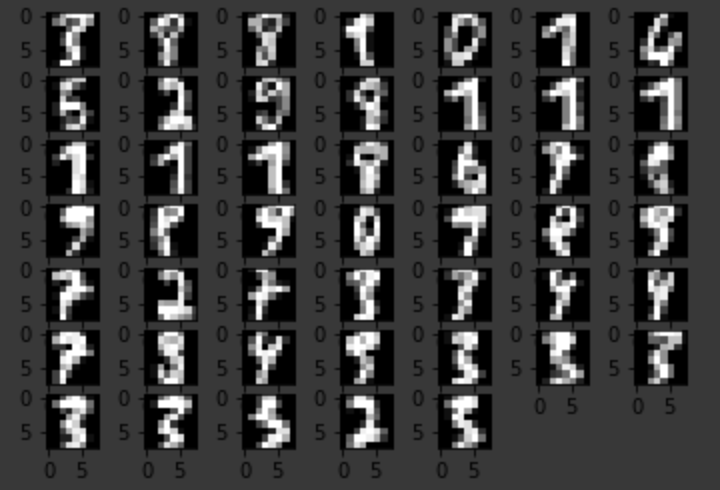
上の画像が人工知能が間違えたデータ一覧です。
ん?判断できるものもあるぞ。
確かに、判別しにくいものもありますが、かなり少ないですね。
この辺りは、私の人工知能の設計の問題があるのだと思います。
もう少し勉強しなおしてきます。
まとめ
今回の実験では、人工知能が間違った問題をみなさんがわかるかどうかを試すものでした。
何かこれをやってほしい等のご要望があれば、コメント欄にいただければと思います。
それでは、この辺りで。


コメント